Castroom

Overview
Castroom is a podcast search engine. It was primarily made to learn how to make a scalable, distributed web crawler using Kubernetes. It is capable of finding 100k+ podcasts within 1-2 hours, and can easily be scaled up even more with one simple command.
Architecture
The source code is split into 3 different folders that represent the 3 different components of the system.
Discovery
Discovery manages the "discovery" of podcasts. This occurs by scouring the iTunes directory for all available podcasts. The crawl job starts here and does a giant BFS operation using multiple workers and Amazon SQS.
Finding all the link that need to be crawled is done using a regex operation. This will crawl all the podcast links, page numbers, and category links. It also enables the crawling of different locale links so podcasts in other languages and regions can be crawled too. (But because of the simple index problem mentioned in the notes above, there is no easy way to search for them)
let clickableUrls = data.match(
/https:\/\/podcasts.apple.com\/\w{2}\/((genre\/[^/]+?-[^/]+?\/id\d{4}(\?letter=.(&page=\d\d?#page)?)?)|podcast\/(([^/]+?-){0,100}([^/]+?)\/id\d{0,12})(?="))/g
);
The discovery folder is further split into master and crawler. The crawler represents the collection of jobs that do the actual crawling for podcasts. A worker node picks up a URL from the queue, visits it, calls iTunes API to get the associated metadata, and then adds all the remaining links to the back of the queue for later processing. It sends all the data gathered to the master node which keeps track of the visited links so there isn't a cycle during processing. The master node maintains a simple key-value store using LevelDB and also takes care of pushing final data to an Amazon Elasticsearch instance for searching.
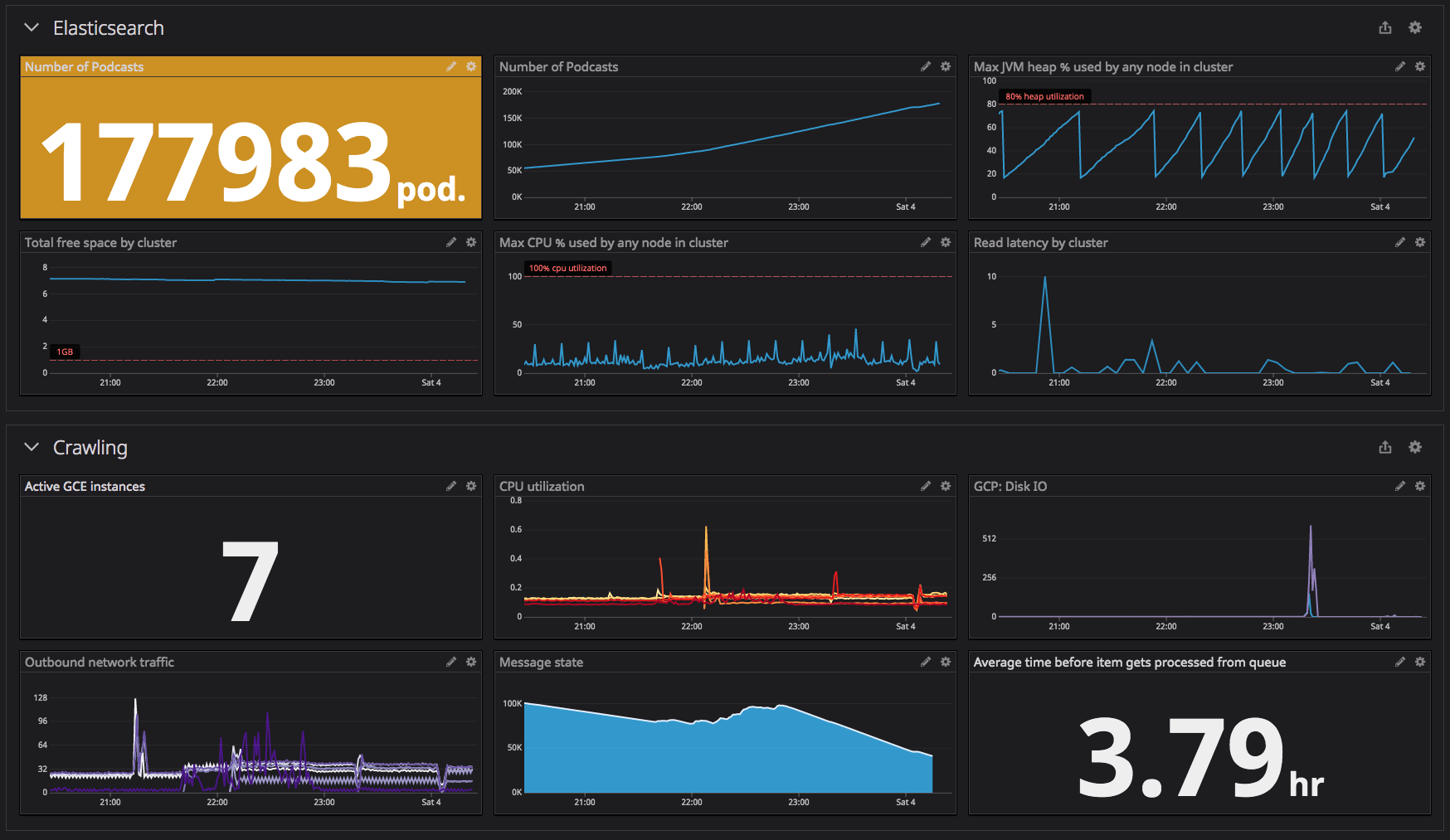 |
|---|
| This was the Datadog dashboard while crawling with 7 instances on GKE |
API
The API is provided by a simple Express server running on Heroku. Its main purpose is to allow the user to query the data from the Elasticsearch instance. When the correct podcast is found, the /feed endpoint is used to get the RSS feed for the podcast. While this could be done from the browser for most podcasts, some feeds don't allow CORS so the request has to get proxied by the server first.
Web
The Web folder contains a React app that is shown to the users at castroom.web.app. Here users can run some demo searches against the crawled database. Since the aim of this project wasn't to create a user-facing product, the webpage is pretty bare in functionality.
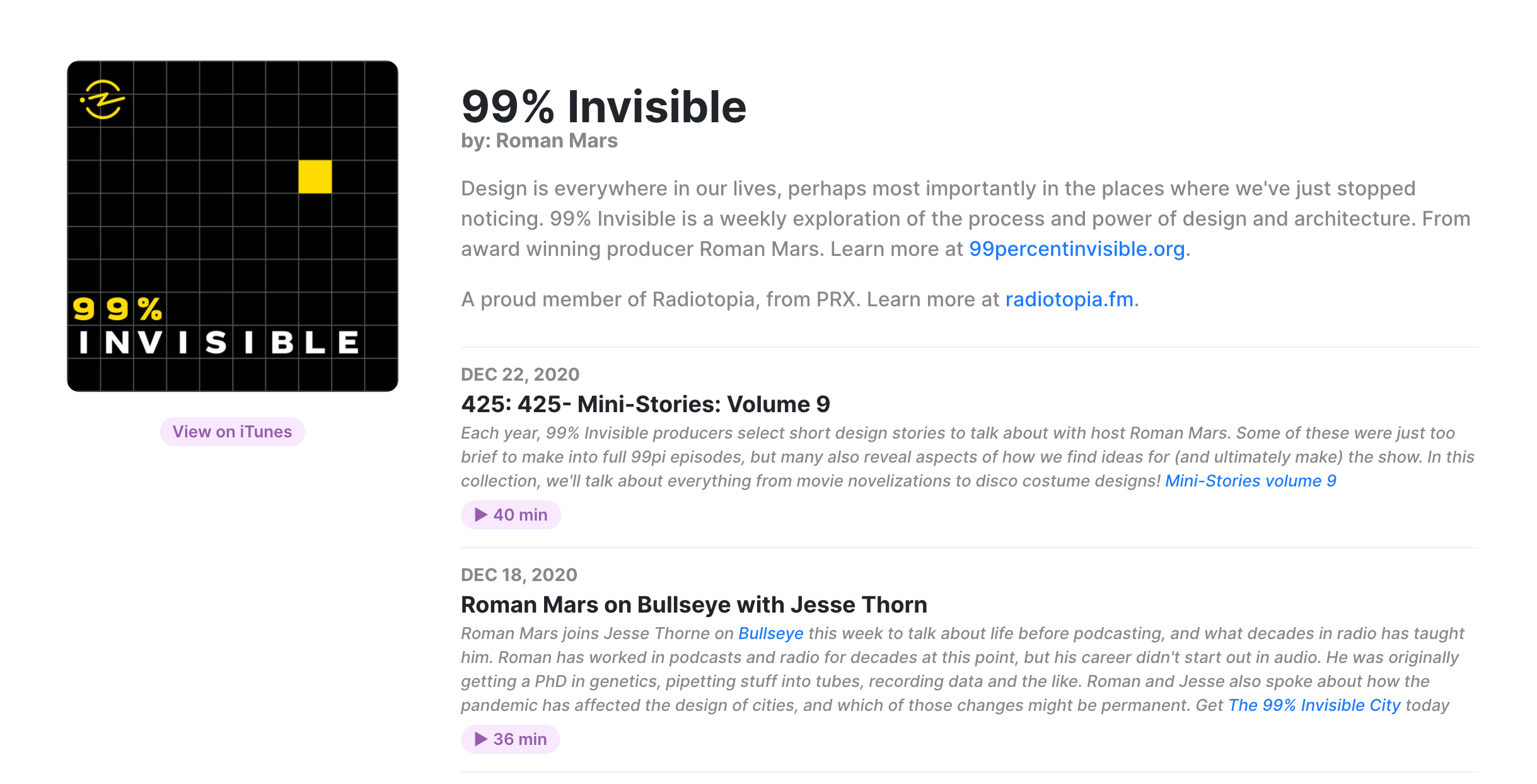 |
|---|
| UI for the podcast details on castroom.web.app |
Putting it together
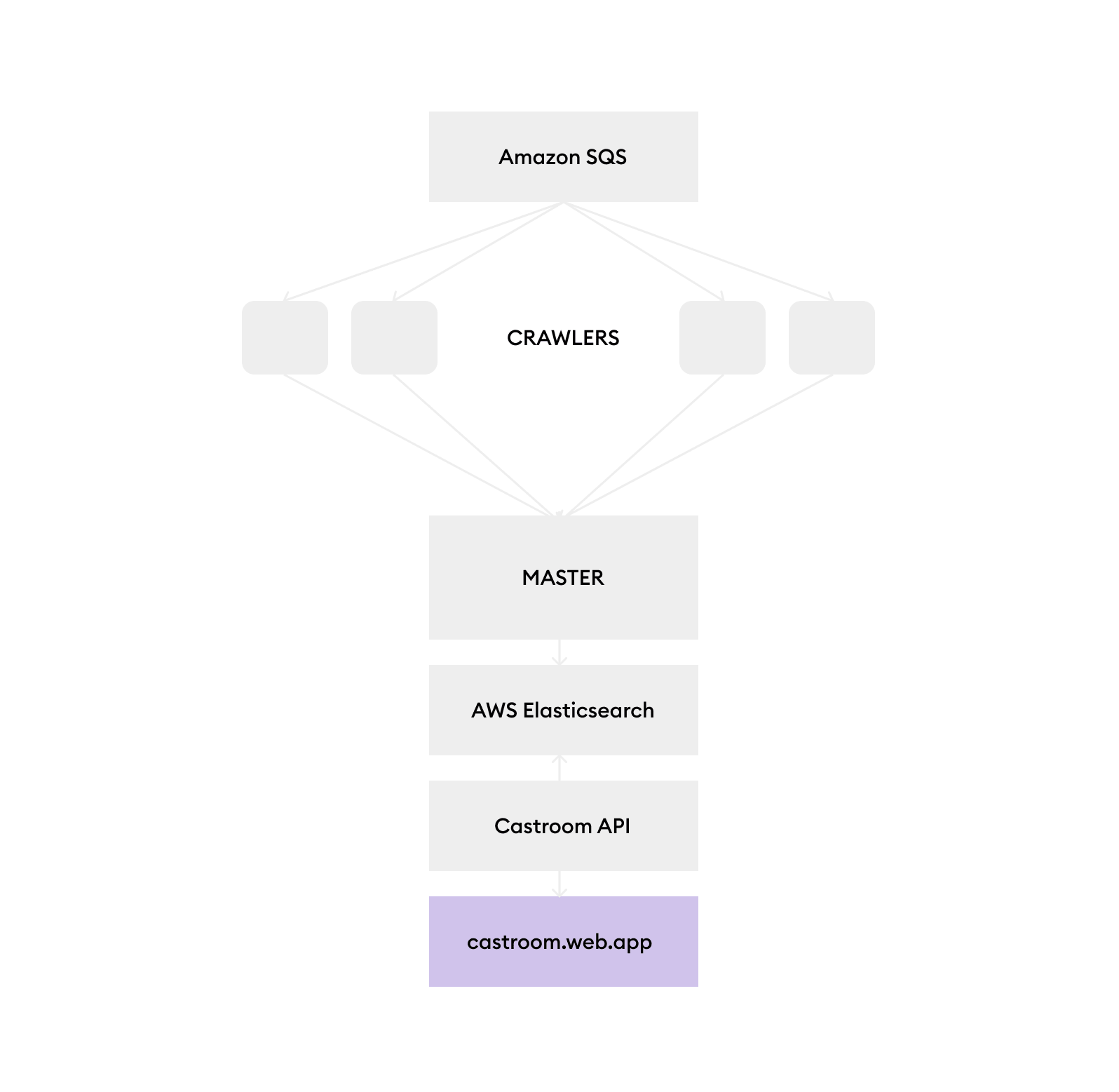
Technologies
- Google Kubernetes Engine
- Amazon Simple Queue Service
- Amazon Elasticsearch Service
- Docker
- Heroku
- Firebase Hosting
- React
- Node.js
- LevelDB
- Datadog
Further Improvements
Elasticsearch is really powerful, but to get it to work like expected, there is a lot of work and ongoing maintenance required. Using the hosted AWS Elasticsearch Service helped with most of this but it was still too heavy for this project. I later found MeiliSearch and Typesense. Both of these focus on creating a search solution for user-faced applications and are much faster at this task than a vanilla Elasticsearch setup. They are both also more lightweight, and therefore, cheaper to host.